
Standard Streams and File Manipulation in Linux: Explained in Detail
This is the second blog of the ongoing Linux Masterclass Series


Three Standard Streams
Stream here means the transfer of data. That data is simple text.
Stdin (Standard Input)
Stdin has the code 0. Linux takes the standard input and gives an output. It can be a standard output or a standard error.
Stdout (Standard Output)
Stdout has the code 1. Standard output can be streamed at three places in your system:
- Terminal Window
- some file
- Given to a pipe, which redirects it however you want.
If you want to store the text output in a file you can use the symbol >.
For example: If you want to store the ls command output in an output.txt file. You can write the command ls > output.txt. If output.txt doesn’t exist, Linux will create it for you automatically.
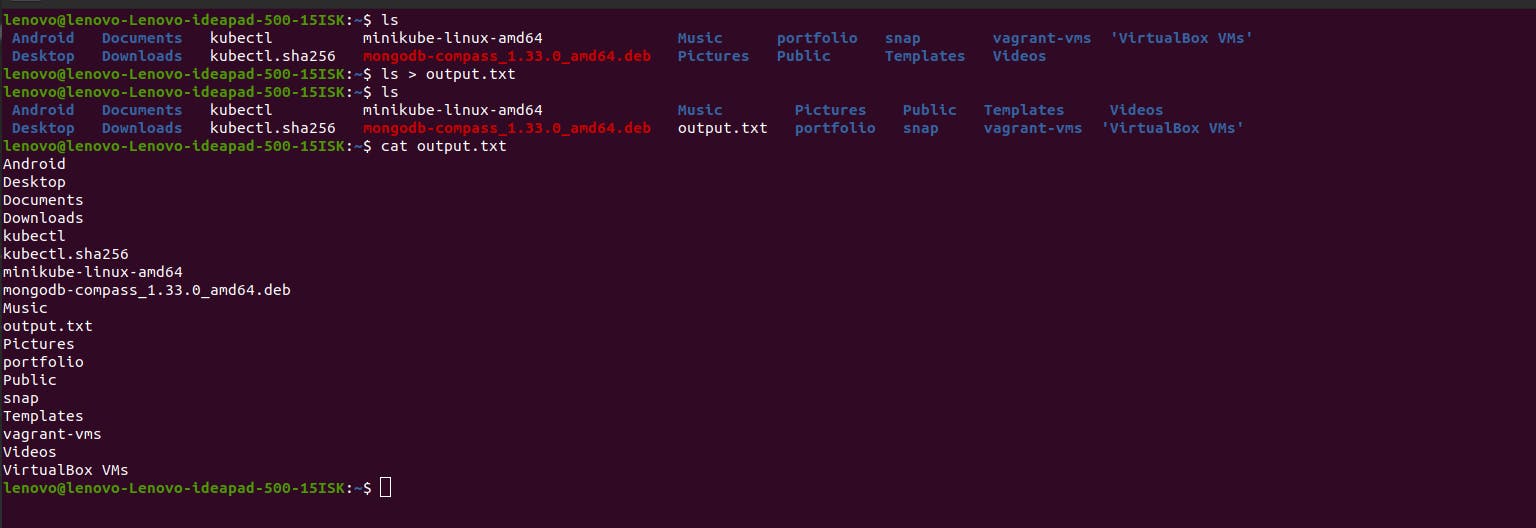
Now, if you go to a different folder and want to store a command’s Stdout, you need to specify the path to output.txt like, ls > ~/output.txt

Notice that the previous entry of the ls output is overwritten with the new one. But you can avoid this and keep adding new entries without overwriting previous ones by using the symbol >> like ls >> output.txt
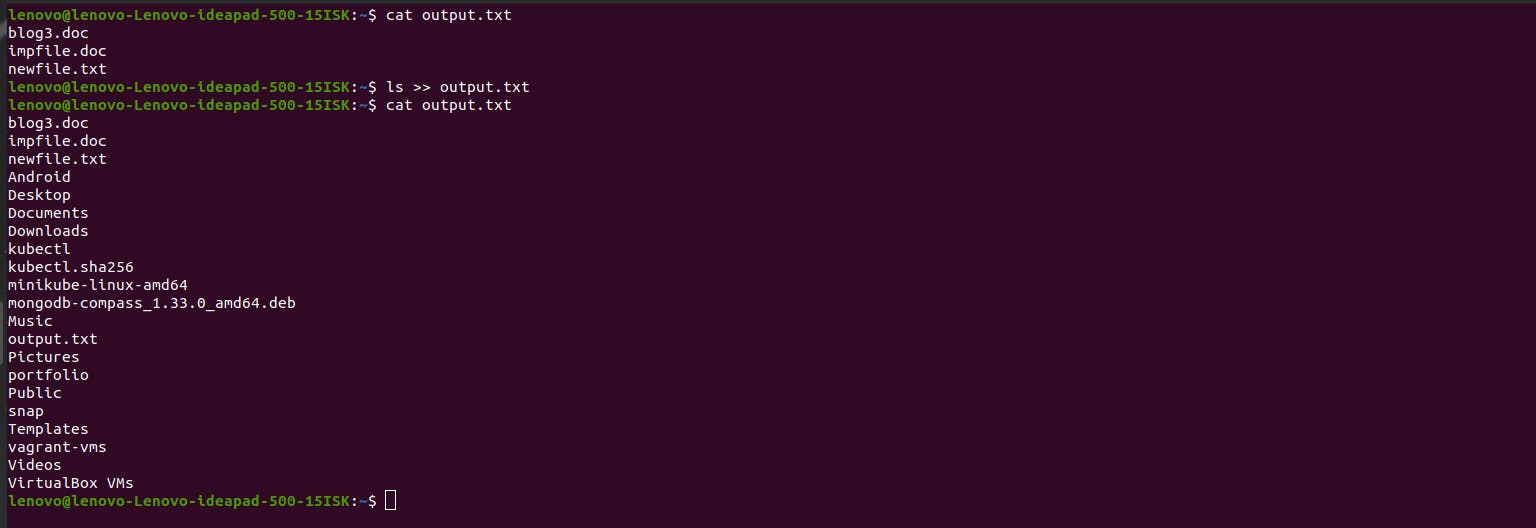
Notice that the previous Documents folder entry is still there while new entries are added.
Controlled Stdout with less command
If you ever try to read a large file in the terminal, for example, with the command ‘cat /var/log/syslog’, it will populate your terminal with an extremely large output. It will become a hindrance for you to scroll up and down. To tackle this, you can do ‘less /var/log/syslog’, this will still display the file data in the terminal, but you can exit it by typing ‘q’ and your output will disappear as it is not populated in the terminal.
Stderr (Standard Error)
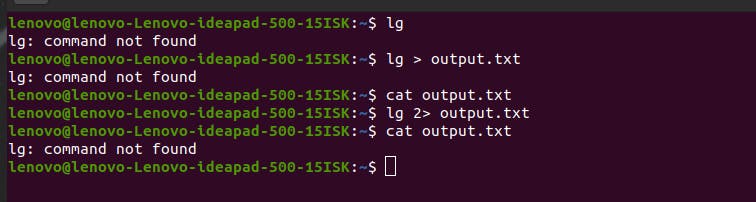
Stderr has the code 2. Let’s understand how Stderr is different from Stdout with an example. If you write the command lg > output.txt, Linux will give a standard error, but will it be saved in output.txt? Let’s see what happens.

As you can see, the output.txt file did get overwritten but is empty. Because a Stderr is not output. It is a Standard error. Output.txt expected a Stdout, hence it is empty.
But let’s say you still want to store Stderr to output.txt. For that, you can use 2> instead of > like ls 2> output.txt. We are writing 2 here because it denotes the Stderr code that Linux recognizes.
How to use the pipe to redirect Standard Output as Standard Input
Let’s say, you want to use the less command with ls -la /etc but if done so, it will give an error as both the output-giving commands are clashing with each other and less is confusing ls with a file/directory name.

You can use pipe ( | ) here to use both ls and less commands together like ls -la /etc | less and it will work just fine.


Let’s understand how did the above command work behind the scenes.
The ls -la /etc part of the command which is a Stdin gave a Stdout in response. But rather than populating on the terminal, it was transferred as a Stdin to the less part of the command by | (pipe)
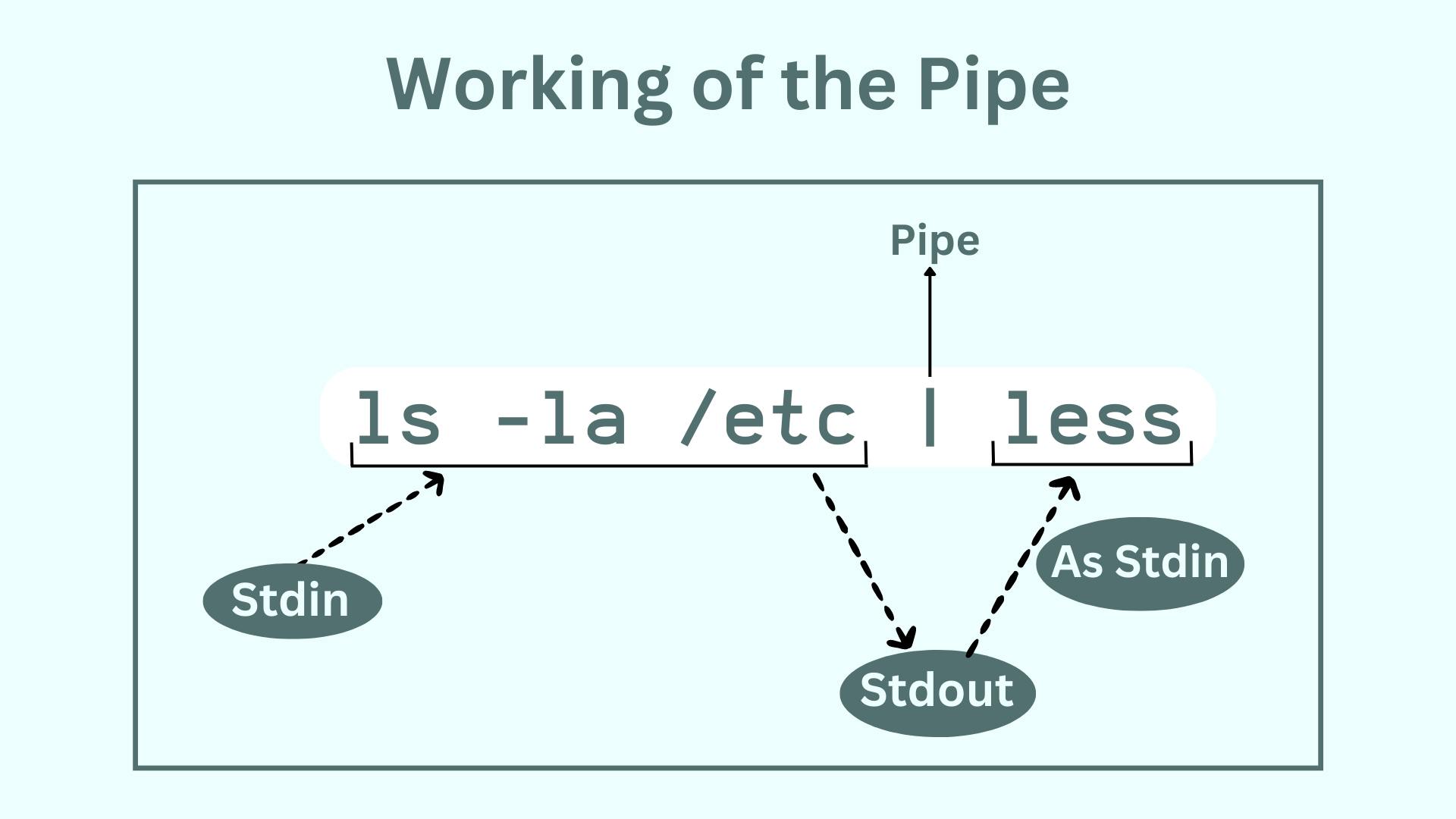
Summary: Pipe allows you to take Stdout of one command and pass it as Stdin to another command.
Environment Variables
If you write echo $HOME, you’ll get something like /home/lenovo. If you do echo $USER, you’ll get lenovo.

Here HOME and USER are environment variables. In simple words, environment variables are useful information that the shell and its child processes use.
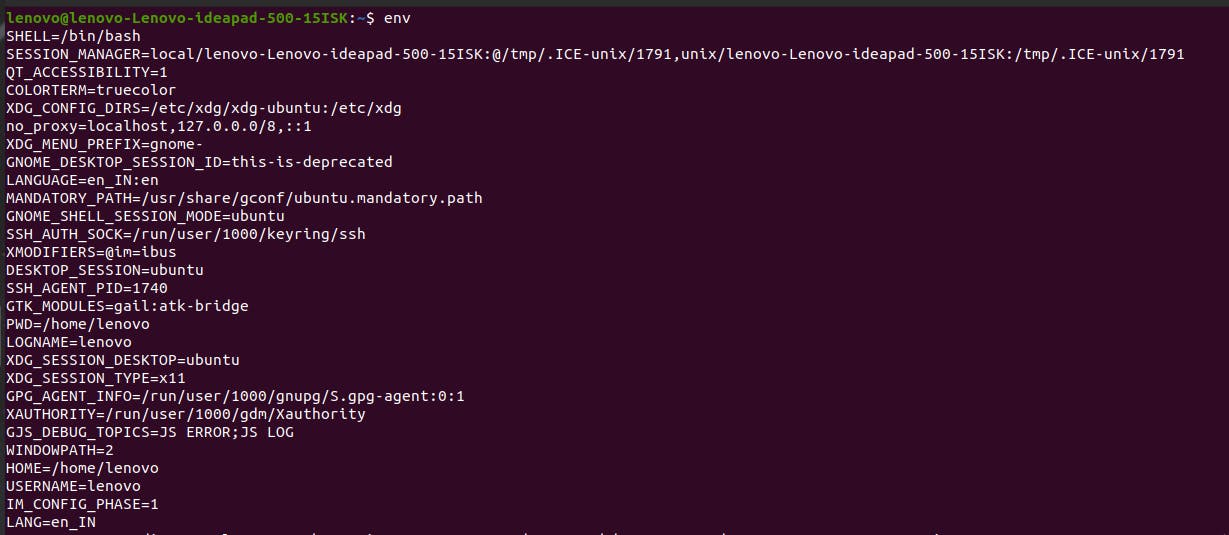
You can check out all the environment variables stored in your system by using the command env
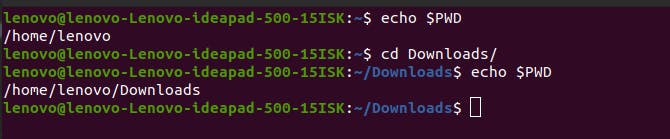
Environment variables are not constant. They keep changing based on what you’re doing in the system. For example, if you write the command echo $PWD where PWD is an environment variable, you’ll get an output like /home/lenovo. But if you change your present working directory with the cd command, the PWD data will change with it as well.
Now if you were wondering how the system gives out your location with the pwd command, it simply maintains an environment variable with that information and gives it out or uses it whenever the user desires.
Everything is a file in Linux, even the commands
If you type echo $PATH, you’ll find all the paths in which Linux checks for the command file that you have entered. If it doesn’t exist, you get the Standard error Command not found. The shell is saying that the file which executes that specific command is not found in any of the file paths stored in the PATH environment variable.

If you want to check the command files in one of these above paths, you can type any path like ls /usr/bin or for a better experience ls /usr/bin | less (to quit less environment, type ‘q’)
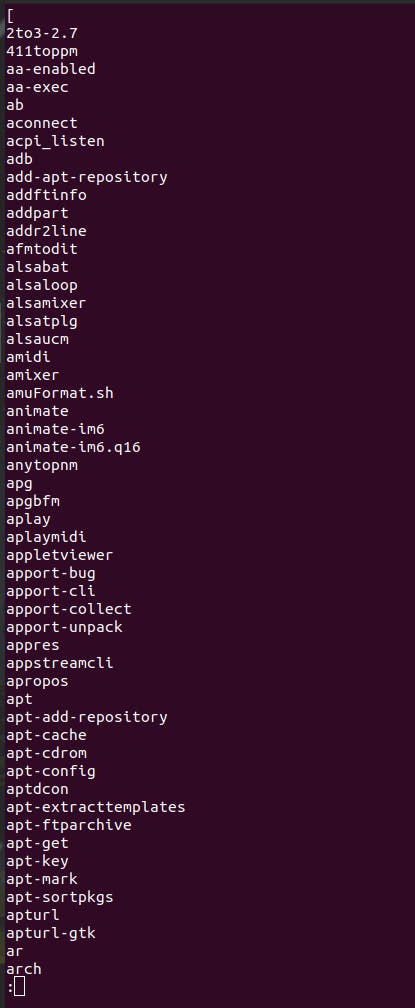
As you can see, the commonly used commands like ‘apt’, ‘ls’, and ‘npm’ exist as files in 'usr/bin'
Basic shell commands to interact with files
head command
If you type head [filename or filepath], it will show you the first ten lines that the file contains. If you want to see more or less lines, you can add the flag ‘-n’ and the number of lines like ‘head -n 5 /var/log/syslog’

tail command
You can do the same thing as head command but for the last ten lines. If you want to control the number of lines you want to display, use the flag -n with the desired number.

If you want to let the Stdout keep updating and populate your terminal, you can use the flag -f
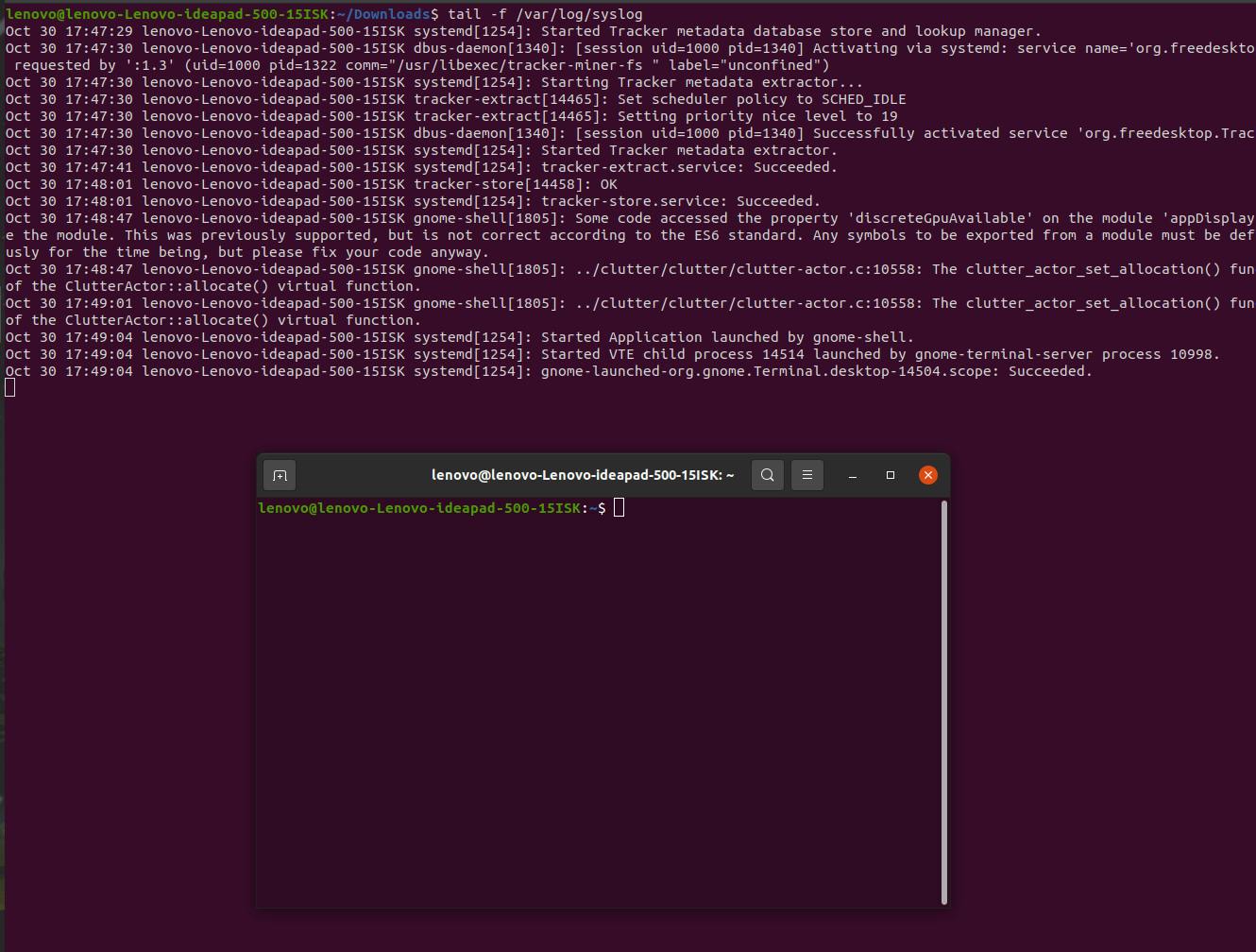
As you can see, when I opened another terminal window, the terminal Stdout got updated with the information about the same (Read the third last line of Standard output).
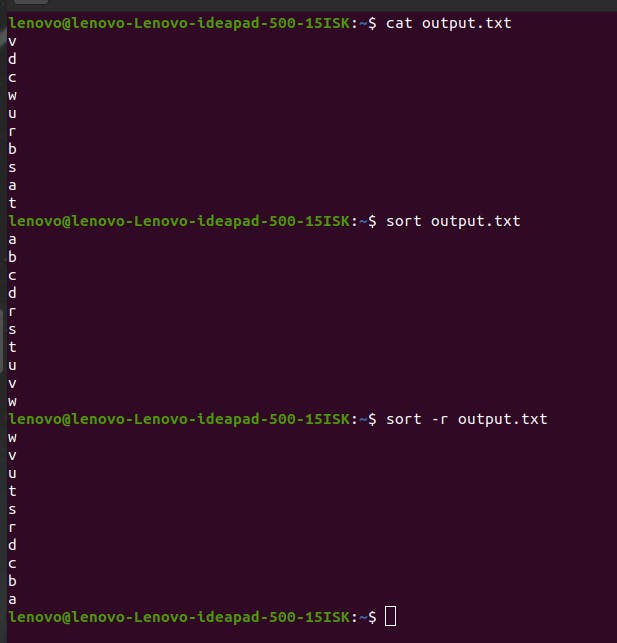
sort command
This helps you sort the file content like below. You can also reverse sort the content with the flag -r
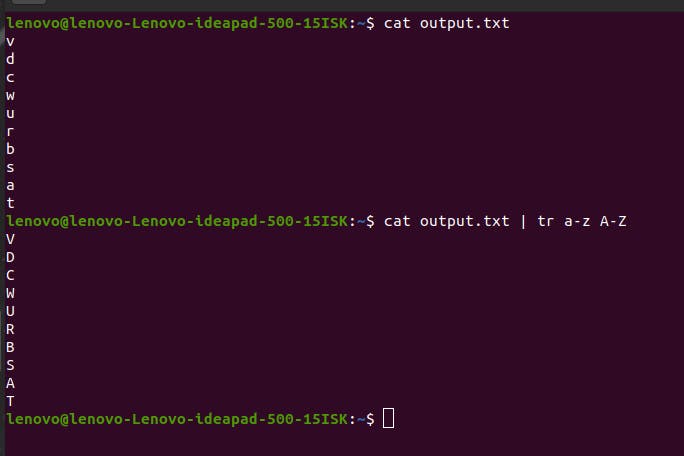
tr command
It takes a Standard input (Stdin) and translates or you can say, deletes and replaces it with a new, translated Standard Output (Stdout). You can use it with a pipe like cat output.txt | tr a-z A-Z
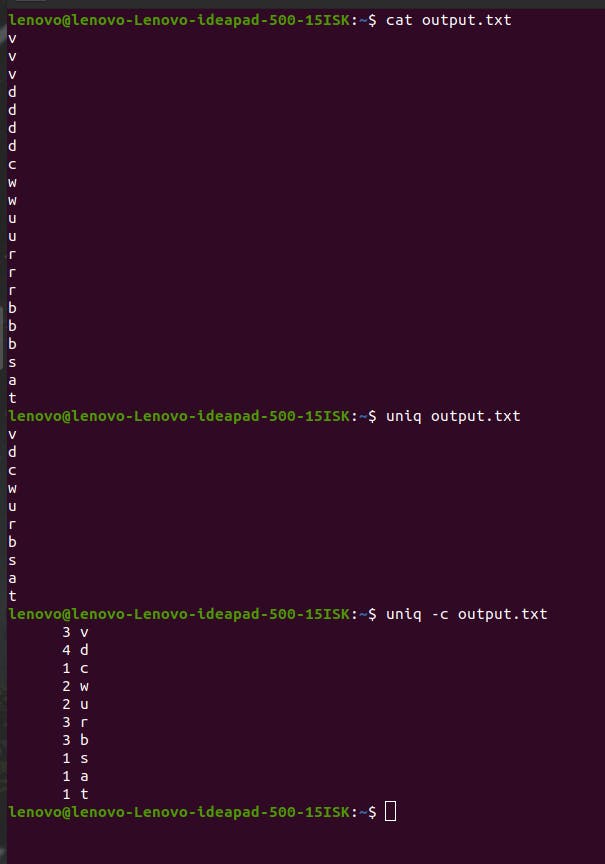
uniq command
Let’s say you have multiple lines with duplicate values, uniq command helps you display only the unique values as standard output. If you use -c flag, it will also show the number of occurrences of each value.
If you only want the non-repeated values, then you can use the flag -u. Only four values are not repeated in the example and hence, displayed.
To see the opposite of this, which is only the duplicated values, you can use the flag -d
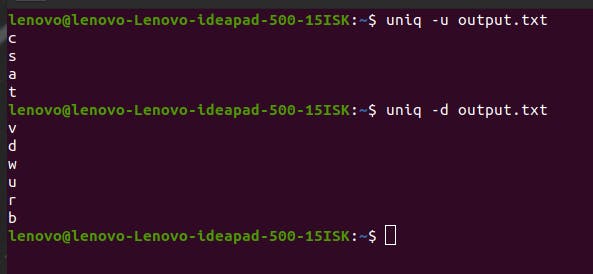
A problem you might face with uniq command
Let’s say the file contains values that are not adjacent to each other, then will the uniq command work?
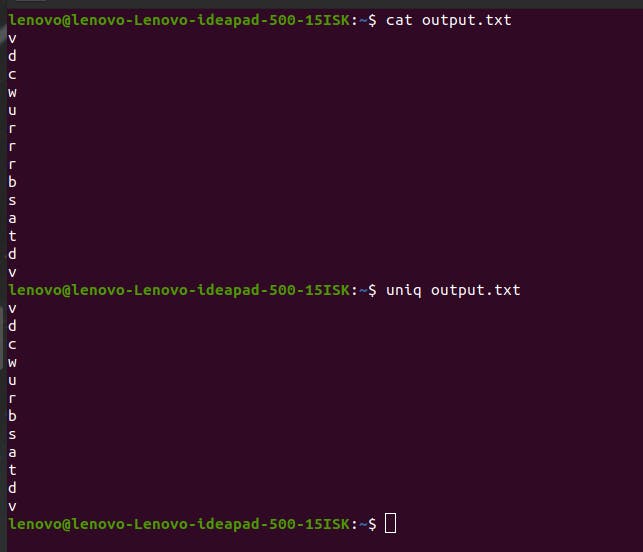
The answer is no. As you can see, the repeated values are v, d, and r. But uniq command is not working on ‘v’ and ‘d’ unlike ‘r’. This is because r’s repetition happens in an adjacent way.
The solution
A handy solution is to use the sort command and transfer its Stdout as Stdin to uniq command via pipe like sort output.txt | uniq
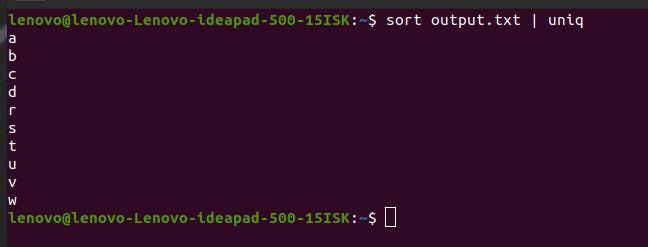
Now you can see that ‘v’ and ‘d’ do not repeat in the Stdout.
wc command
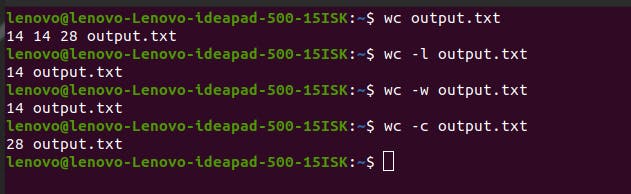
wc command shows multiple count types of a file. If you write the command wc output.txt, it will give you three digits, which denote the number of lines, words and file size.
If you write wc -l [filename or path], you’ll get only the number of lines.
If you write wc -w [filename or path], you’ll get only the number of words.
If you write wc -c [filename or path], you’ll get only the size of the file in bytes.
grep command
It allows you to search files with the help of characters and regular expressions. For example, if you write env | grep PWD, you’ll get the search results with files that have PWD in their name. env command produces a standard output and pipe symbol (|) transfers it to the grep command as standard input.

Not only it shows you PWD, but also OLDPWD, which means the previous directory you were in. If you write cd - command, it will send you back to that directory (OLDPWD).
Thank you for reading :)
To read the previous blog of this Linux Series, click here
To see a video lecture of this blog, go to this youtube video
Follow me on Twitter here
Do comment your thoughts or anything unique you learned below!